The computational understanding of interface (UI) is an essential action towards attaining smart UI habits. Formerly, we examined different UI modeling jobs, consisting of widget captioning, screen summarization, and command grounding, that deal with varied interaction circumstances such as automation and availability. We likewise showed how artificial intelligence can assist user experience specialists enhance UI quality by identifying tappability confusion and supplying insights for enhancing UI style. These works together with those established by others in the field have actually showcased how deep neural networks can possibly change end user experiences and the interaction style practice.
With these successes in resolving specific UI jobs, a natural concern is whether we can acquire fundamental understandings of UIs that can benefit particular UI jobs. As our very first effort to address this concern, we established a multi-task design to deal with a variety of UI jobs at the same time. Although the work made some development, a couple of difficulties stay. Previous UI designs greatly depend on UI view hierarchies— i.e., the structure or metadata of a mobile UI screen like the File Item Design for a website– that enable a design to straight get comprehensive details of UI items on the screen (e.g., their types, text material and positions). This metadata has actually offered previous designs benefits over their vision-only equivalents. Nevertheless, view hierarchies are not constantly available, and are typically damaged with missing out on things descriptions or misaligned structure details. As an outcome, in spite of the short-term gains from utilizing view hierarchies, it might eventually obstruct the design efficiency and applicability. In addition, previous designs needed to handle heterogeneous details throughout datasets and UI jobs, which typically led to complicated design architectures that were hard to scale or generalize throughout jobs.
In “ Spotlight: Mobile UI Comprehending utilizing Vision-Language Designs with a Focus“, accepted for publication at ICLR 2023, we provide a vision-only technique that intends to attain basic UI understanding entirely from raw pixels. We present a unified technique to represent varied UI jobs, the details for which can be widely represented by 2 core methods: vision and language. The vision method records what an individual would see from a UI screen, and the language method can be natural language or any token series associated with the job. We show that Spotlight considerably enhances precision on a variety of UI jobs, consisting of widget captioning, screen summarization, command grounding and tappability forecast.
 |
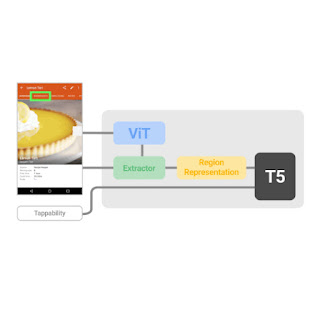
Spotlight Design
The Spotlight design input consists of a tuple of 3 products: the screenshot, the area of interest on the screen, and the text description of the job. The output is a text description or reaction about the area of interest. This easy input and output representation of the design is meaningful to catch different UI jobs and enables scalable design architectures. This model style enables a spectrum of discovering techniques and setups, from task-specific fine-tuning, to multi-task knowing and to few-shot knowing. The Spotlight design, as shown in the above figure, leverages existing architecture foundation such as ViT and T5 that are pre-trained in the high-resourced, basic vision-language domain, which enables us to develop on top of the success of these basic domain designs.
Due to the fact that UI jobs are typically interested in a particular things or location on the screen, which needs a design to be able to concentrate on the things or location of interest, we present a Focus Area Extractor to a vision-language design that allows the design to focus on the area because of the screen context.
In specific, we create an Area Summarizer that gets a hidden representation of a screen area based upon ViT encodings by utilizing attention questions created from the bounding box of the area (see paper for more information). Particularly, each coordinate (a scalar worth, i.e., the left, top, right or bottom) of the bounding box, represented as a yellow box on the screenshot, is very first ingrained by means of a multilayer perceptron (MLP) as a collection of thick vectors, and after that fed to a Transformer design along their coordinate-type embedding. The thick vectors and their matching coordinate-type embeddings are color coded to suggest their association with each coordinate worth. Coordinate questions then address evaluate encodings output by ViT by means of cross attention, and the last attention output of the Transformer is utilized as the area representation for the downstream decoding by T5.
 |
| A target area on the screen is summed up by utilizing its bounding box to query into screen encodings from ViT by means of attentional systems. |
Outcomes
We pre-train the Spotlight design utilizing 2 unlabeled datasets (an internal dataset based upon C4 corpus and an internal mobile dataset) with 2.5 million mobile UI screens and 80 million websites. We then independently tweak the pre-trained design for each of the 4 downstream jobs (captioning, summarization, grounding, and tappability). For widget captioning and screen summarization jobs, we report CIDEr ratings, which determine how comparable a design text description is to a set of referrals developed by human raters. For command grounding, we report precision that determines the portion of times the design effectively finds a target things in reaction to a user command. For tappability forecast, we report F1 ratings that determine the design’s capability to inform tappable items from untappable ones.
In this experiment, we compare Spotlight with a number of benchmark designs. Widget Caption utilizes view hierarchy and the image of each UI challenge produce a text description for the things. Likewise, Screen2Words utilizes view hierarchy and the screenshot in addition to auxiliary functions (e.g., app description) to produce a summary for the screen. In the exact same vein, VUT integrates screenshots and view hierarchies for carrying out numerous jobs. Lastly, the initial Tappability design leverages things metadata from view hierarchy and the screenshot to forecast things tappability. Taperception, a follow-up design of Tappability, utilizes a vision-only tappability forecast technique. We take a look at 2 Spotlight design variations with regard to the size of its ViT foundation, consisting of B/16 and L/16 Spotlight significantly went beyond the advanced throughout 4 UI modeling jobs.
| Design | Captioning | Summarization | Grounding | Tappability | |||||||||||
| Standards. |
Widget Caption | 97. | -. | -. | -. | ||||||||||
| Screen2Words | -. | 61.3. | -. | -. | |||||||||||
| VUT | 99.3. | 65.6. | 82.1. | -. | |||||||||||
| Taperception | -. | -. | -. | 85.5. | |||||||||||
| Tappability | -. | -. | -. | 87.9. | |||||||||||
| Spotlight. | B/16 | 136.6. | 103.5. | 95.7. | 86.9. | ||||||||||
| L/16 | 141.8 | 106.7 | 95.8 | 88.4 |
We then pursue a more difficult setup where we ask the design to find out numerous jobs at the same time since a multi-task design can considerably minimize design footprint As displayed in the table listed below, the experiments revealed that our design still carries out competitively.
| Design | Captioning | Summarization | Grounding | Tappability | ||||||||||
| VUT multi-task. | 99.3. | 65.1. | 80.8. | -. | ||||||||||
| Spotlight B/16. | 140. | 102.7 | 90.8. | 89.4. | ||||||||||
| Spotlight L/16. | 141.3 | 99.2. | 94.2 | 89.5 |
To comprehend how the Area Summarizer allows Spotlight to concentrate on a target area and pertinent locations on the screen, we examine the attention weights (which suggest where the design attention is on the screenshot) for both widget captioning and screen summarization jobs. In the figure listed below, for the widget captioning job, the design anticipates “choose Chelsea group” for the checkbox on the left side, highlighted with a red bounding box. We can see from its attention heatmap (which shows the circulation of attention weights) on the right that the design finds out to address not just the target area of the check box, however likewise the text “Chelsea” on the far delegated produce the caption. For the screen summarization example, the design anticipates “page showing the tutorial of a knowing app” offered the screenshot left wing. In this example, the target area is the whole screen, and the design finds out to address fundamental parts on the screen for summarization.
 |
| For the widget captioning job, the attention heatmap reveals the design addressing the checkbox, i.e., the target things, and the text label on its left when creating a caption for the things. The red bounding box in the figure is for illustration functions. |
 |
| For the screen summarization job that the target area confines the whole screen, the attention heatmap reveals the design addressing different places on the screen that add to creating the summary. |
Conclusion
We show that Spotlight surpasses previous techniques that utilize both screenshots and view hierarchies as the input, and develops advanced outcomes on numerous representative UI jobs. These jobs vary from availability, automation to interaction style and examination. Our vision-only technique for mobile UI understanding minimizes the requirement to utilize view hierarchy, enables the architecture to quickly scale and gain from the success of big vision-language designs pre-trained for the basic domain. Compared to current big vision-language design efforts such as Flamingo and PaLI, Spotlight is reasonably little and our experiments reveal the pattern that bigger designs yield much better efficiency. Spotlight can be quickly used to more UI jobs and possibly advance the fronts of numerous interaction and user experience jobs.
Recommendation
We thank Mandar Joshi and Tao Li for their assistance in processing the web pre-training dataset, and Chin-Yi Cheng and Forrest Huang for their feedback for checking the paper. Thanks to Tom Small for his assistance in developing animated figures in this post.