Support knowing (RL) algorithms can discover abilities to resolve decision-making jobs like playing video games, allowing robotics to get things, or perhaps enhancing microchip styles Nevertheless, running RL algorithms in the real life needs pricey active information collection Pre-training on varied datasets has actually shown to allow data-efficient fine-tuning for specific downstream jobs in natural language processing (NLP) and vision issues. In the exact same method that BERT or GPT-3 designs supply general-purpose initialization for NLP, big RL– pre-trained designs might supply general-purpose initialization for decision-making. So, we ask the concern: Can we allow comparable pre-training to speed up RL techniques and produce a general-purpose “foundation” for effective RL throughout numerous jobs?
In “ Offline Q-learning on Diverse Multi-Task Data Both Scales and Generalizes“, to be released at ICLR 2023, we talk about how we scaled offline RL, which can be utilized to train worth functions on formerly gathered fixed datasets, to supply such a basic pre-training approach. We show that Scaled Q-Learning utilizing a varied dataset suffices to discover representations that assist in quick transfer to unique jobs and quick online knowing on brand-new variations of a job, enhancing substantially over existing representation knowing methods and even Transformer-based techniques that utilize much bigger designs.
 |
Scaled Q-learning: Multi-task pre-training with conservative Q-learning
To supply a general-purpose pre-training method, offline RL requires to be scalable, enabling us to pre-train on information throughout various jobs and use meaningful neural network designs to get effective pre-trained foundations, specialized to specific downstream jobs. We based our offline RL pre-training approach on conservative Q-learning (CQL), an easy offline RL approach that integrates requirement Q-learning updates with an extra regularizer that reduces the worth of hidden actions. With discrete actions, the CQL regularizer is comparable to a requirement cross-entropy loss, which is an easy, one-line adjustment on basic deep Q-learning. A couple of important style choices made this possible:.
- Neural network size: We discovered that multi-game Q-learning needed big neural network architectures. While previous techniques frequently utilized reasonably shallow convolutional networks, we discovered that designs as big as a ResNet 101 resulted in substantial enhancements over smaller sized designs.
- Neural network architecture: To discover pre-trained foundations that work for brand-new video games, our last architecture utilizes a shared neural network foundation, with different 1-layer heads outputting Q-values of each video game. This style prevents disturbance in between the video games throughout pre-training, while still offering enough information sharing to discover a single shared representation. Our shared vision foundation likewise made use of a found out position embedding (comparable to Transformer designs) to monitor spatial details in the video game.
- Representational regularization: Current work has actually observed that Q-learning tends to experience representational collapse problems, where even big neural networks can stop working to discover reliable representations. To combat this concern, we utilize our previous work to stabilize the last layer functions of the shared part of the Q-network. In addition, we made use of a categorical distributional RL loss for Q-learning, which is understood to supply richer representations that enhance downstream job efficiency.
The multi-task Atari criteria
We assess our method for scalable offline RL on a suite of Atari video games, where the objective is to train a single RL representative to play a collection of video games utilizing heterogeneous information from low-grade (i.e., suboptimal) gamers, and after that utilize the resulting network foundation to rapidly discover brand-new variations in pre-training video games or entirely brand-new video games. Training a single policy that can play various Atari video games is hard enough even with basic online deep RL techniques, as each video game needs a various technique and various representations. In the offline setting, some prior works, such as multi-game choice transformers, proposed to do without RL completely, and rather use conditional replica knowing in an effort to scale with big neural network architectures, such as transformers. Nevertheless, in this work, we reveal that this type of multi-game pre-training can be done successfully by means of RL by utilizing CQL in mix with a couple of cautious style choices, which we explain listed below.
Scalability on training video games
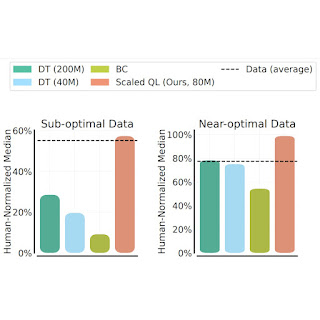
We assess the Scaled Q-Learning approach’s efficiency and scalability utilizing 2 information structures: (1) near optimum information, including all the training information appearing in replay buffers of previous RL runs, and (2) poor quality information, including information from the very first 20% of the trials in the replay buffer (i.e., just information from extremely suboptimal policies). In our outcomes listed below, we compare Scaled Q-Learning with an 80-million specification design to multi-game choice transformers (DT) with either 40-million or 80-million specification designs, and a behavioral cloning (replica knowing) standard (BC). We observe that Scaled Q-Learning is the only method that enhances over the offline information, achieving about 80% of human stabilized efficiency.
 |
Even more, as revealed listed below, Scaled Q-Learning enhances in regards to efficiency, however it likewise delights in beneficial scaling residential or commercial properties: simply as how the efficiency of pre-trained language and vision designs enhances as network sizes grow, enjoying what is normally referred as “power-law scaling”, we reveal that the efficiency of Scaled Q-learning delights in comparable scaling residential or commercial properties. While this might be unsurprising, this type of scaling has actually been evasive in RL, with efficiency frequently weakening with bigger design sizes. This recommends that Scaled Q-Learning in mix with the above style options much better opens the capability of offline RL to use big designs.
 |
Fine-tuning to brand-new video games and variations
To assess fine-tuning from this offline initialization, we think about 2 settings: (1) tweak to a brand-new, completely hidden video game with a percentage of offline information from that video game, representing 2M shifts of gameplay, and (2) tweak to a brand-new variation of the video games with online interaction. The fine-tuning from offline gameplay information is highlighted listed below. Keep in mind that this condition is typically more beneficial to imitation-style techniques, Choice Transformer and behavioral cloning, because the offline information for the brand-new video games is of reasonably premium. However, we see that in many cases Scaled Q-learning enhances over alternative methods (80% typically), in addition to devoted representation discovering techniques, such as MAE or CPC, which just utilize the offline information to discover graphes instead of worth functions.
 |
In the online setting, we see even bigger enhancements from pre-training with Scaled Q-learning. In this case, representation knowing techniques like MAE yield very little enhancement throughout online RL, whereas Scaled Q-Learning can effectively incorporate anticipation about the pre-training video games to substantially enhance the last rating after 20k online interaction actions.
These outcomes show that pre-training generalist worth function foundations with multi-task offline RL can substantially increase efficiency of RL on downstream jobs, both in offline and online mode. Keep in mind that these fine-tuning jobs are rather hard: the numerous Atari video games, and even variations of the exact same video game, vary substantially in look and characteristics. For instance, the target obstructs in Breakout vanish in the variation of the video game as revealed listed below, making control hard. Nevertheless, the success of Scaled Q-learning, especially as compared to graph knowing strategies, such as MAE and CPC, recommends that the design remains in reality discovering some representation of the video game characteristics, instead of simply offering much better visual functions.
 |
| Fine-tuning with online RL for variations of the video game Highway, Hero, and Breakout. The brand-new variation utilized in fine-tuning is displayed in the bottom row of each figure, the initial video game seen in pre-training remains in the leading row. Fine-tuning from Scaled Q-Learning substantially outshines MAE (a graph knowing approach) and gaining from scratch with single-game DQN. |
Conclusion and takeaways
We provided Scaled Q-Learning, a pre-training approach for scaled offline RL that develops on the CQL algorithm, and showed how it allows effective offline RL for multi-task training. This work made preliminary development towards allowing more useful real-world training of RL representatives as an option to pricey and complicated simulation-based pipelines or massive experiments. Maybe in the long run, comparable work will result in typically capable pre-trained RL representatives that establish broadly relevant expedition and interaction abilities from massive offline pre-training. Verifying these outcomes on a more comprehensive series of more reasonable jobs, in domains such as robotics (see some preliminary outcomes) and NLP, is an essential instructions for future research study. Offline RL pre-training has a great deal of capacity, and we anticipate that we will see numerous advances in this location in future work.
Recognitions
This work was done by Aviral Kumar, Rishabh Agarwal, Xinyang Geng, George Tucker, and Sergey Levine. Unique thanks to Sherry Yang, Ofir Nachum, and Kuang-Huei Lee for aid with the multi-game choice transformer codebase for assessment and the multi-game Atari criteria, and Tom Small for illustrations and animation.